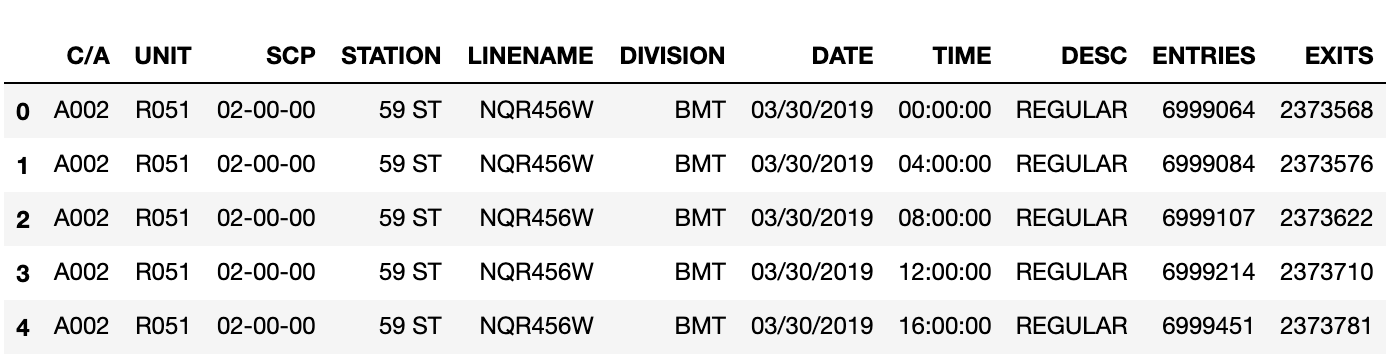
Interpreting Coefficients for MLB Linear Regression Models
For my second project at Metis I decided to use linear regression to see if I could predict how good of a career a Major League Baseball (MLB) player would have based on their minor league statistics. I imagined that I had been asked to do this by a professional baseball General Manager (GM). This is useful because the teams draft 18-20 year olds who need to spend years in the minor leagues before they have the skills necessary to be effective players at the top level. So while GMs are of course very focused on the current professional team, they need to always be developing talent that will be ready to contribute to the major league team years down the line. In fact, they need to know exactly how good each player on their minor league teams is expected to be in the majors in order to make decisions about trades and future draft picks.

I scraped minor league stats and MLB ABs from baseball-reference.com and used OLS, Ridge, and Lasso linear regression models to predict values. I ran into a problem at the beginning when I realized that a little more than half of the players I had scraped from minor league rosters didn’t make the pros. The model was having a hard problem predicting when most of the true values were zero. Thus, I changed the problem to predicting how good of a career a player will have assuming we know they make it to the MLB. To solve this problem, I only trained my models with players who had at least 1 MLB AB. It is interesting to note that my initial problem statement actually included two separate problems: 1) Will a player in the minors make it to the MLB and 2)If they make it, how many ABs will they have in their career. For the purposes of this project, I focused on the latter but the former is also an interesting question.
First, I trained an OLS model using the Stats Models package in python and took a look to see what my baseline model showed. The dependent variable or value we are trying to predict is MLB AB per season. I chose to add “per season” in order to normalize the data a bit. Players have careers of different lengths so it was not fair to compare apples to apples.
Analysis
Instantly, it was clear that we would not be using this model to predict MLB ABs for players because the adjusted R squared value was 0.359. That means the independent variables were only responsible for 35.9% of the variance in the dependent variable. So if we try to predict MLB ABs for players we’re going to be off most of the time. However, that doesn’t mean this model is useless. We can still make meaningful conclusions from the coefficients for each independent variable. Below you can see the coefficients for each feature or independent value in the model.
| Feature | Coefficients |
|---|---|
| Runs per AB | 764.62 |
| Strikeouts per AB | -749.73 |
| Bats = Both | 373.93 |
| Bats = Left | 370.16 |
| Bats = Right | 363.33 |
| OPS | 334.07 |
| Position = Shortstop | 197.46 |
| Position = Second Baseman | 187.68 |
| Position = First Baseman | 186.25 |
| Position = Third Baseman | 183.88 |
| Position = Outfielder | 182.47 |
| Position = Catcher | 169.68 |
| School | 36.00 |
| Debut Age | -30.27 |
| BMI | 5.32 |
| Draft | 0.88 |
So first of all, the Stats Models package displays a lot of more useful information than this but for simplicity I’m focusing on the coefficients. Here are the conclusions we can draw from this:
- Runs per AB has the highest impact on MLB ABs per season. For an increase in 1 run per AB, the MLB ABs per season for that player changes by ~764.
- Strikeouts per AB has the 2nd highest impact on MLB ABs per season. It has a negative coefficient which means that the fewer strikeouts a player had in the minors the more MLB ABs they had. Specifically, for a decrease in 1 strikeout per AB the MLB AB per season for that player changes by ~749 ABs per season
- Next, the three Bats coefficients had the highest numbers. Bats was my way of showing handedness. In baseball, you stand on a different side of the plate during an at-bat depending on if you’re right-handed or left-handed. Some players have even trained themselves to bat on both sides of the plate which can give them an extra advantage. While all these coefficients are high, notice that all the coefficients have nearly exactly the same value. In linear regressions this should raise some alarm. The fact that the coefficients for these three features are all the same means they all have the same effect and are likely collinear with each other. This means including all of them in the final model is not necessary as a result. And for our purposes, since all these coefficients are the same it means they all have a similar impact so it doesn’t make any difference to your MLB ABs if you’re right handed or left-handed.
- The next strongest impact is OPS or On-base plus slugging percentage. This is a fancy new statistic that was introduced in baseball recently that combines how often you get on base with how often you hit doubles, tripes and home runs. It is one of a few attempts recently to encapsulate how good a player is in one statistic. It looks like it’s more than just me that’s interested in this problem!
- You can see the same thing with what position you play as you did with handedness. All of these values are very close and that tells us they all have the same impact. Therefore, no one position seems to give a player an advantage in having a better MLB career than another. However, if we were to add fielding data for each observation I’d imagine this would change.
- Finally, whether a player went to college and when they made it to MLB seemed to make a very small impact on MLB ABs per season. Player BMI and what round they were drafted in had almost no impact.
Ridge Regression
From the above, you can see how I interpreted the model to figure out what features were important and which ones were not. However, I still had too many features and issues with collinearity. When this happens, OLS tends to produce high variance and overfit. To solve that problem, I turned to a Ridge regression model which fits the model based on a different loss function. This loss function penalizes the model for having high coefficient values and therefore Ridge shrinks the coefficients down. The ultimate effect is it introduces some bias which reduces variance.
So let’s take a look at the coefficients for the Ridge model output:
| Feature | Coefficients |
|---|---|
| Debut Age | -71.49 |
| Strikeouts per AB | -39.34 |
| OPS | 25.96 |
| Runs per AB | 17.33 |
| School | 16.79 |
| Draft | -11.18 |
| BMI | 10.25 |
| Position = Catcher | -4.86 |
| Position = Shortstop | 3.19 |
| Bats = Both | 2.95 |
| Position = First Baseman | 2.47 |
| Position = Second Baseman | 1.77 |
| Bats = Left | -1.32 |
| Position = Outfielder | -0.92 |
| Bats = Right | -0.91 |
| Position = Third Baseman | -0.74 |
The first thing we notice is all the coefficients are much smaller. The order has changed slightly as well.
According to Ridge, debut age now has the highest impact. While it’s strange that this has shot up so much from it’s rank in the OLS coefficients, it does make sense. Of course, the earlier someone debuts in the MLB, the more likely they are to have more at-bats. So this doesn’t give us any new insight.
The next three features were also highly rated by the OLS model. So we can feel more confident that high runs per AB, low strikeouts per AB, and high OPS in the minors are correlated with longer careers in the MLB. Playing college baseball also seems to help players have longer professional careers as well. After that though, nothing else seems to be tremendously impactful. It is nice to see, however, that the conclusions for handedness and position from the OLS model were validated by the Ridge model. You can see that all the coefficients for those features are close to zero meaning they provide very little impact. We had come to the same conclusion by noticing that their OLS coefficients were all about the same.
Conclusions
Unfortunately, we still cannot predict anything with the Ridge model. According to this model, the feature that has the most predictive power on the number of ABs per season a player will have in the MLB is the age they enter the league. That’s not very useful. Perhaps predicting MLB career length is an incredibly difficult task and debut age really is the most impactful feature. If not, we need to find more features to add to our model or maybe we can change the dependent variable to MLB OPS or WAR. In the meantime, we can also develop a classification model that can tell us if a minor league player will even make it to the pros or not. So how is this helpful? Let’s say you’re a professional baseball GM and you only had this model to help you draft players. You still won’t know who exactly is going to have a long MLB career but if you see a college graduate with a low strikeout rate, lots of runs, and a high OPS you might just perk up. This model can tell us which of the many baseball statistics to pay attention to when evaluating players. Finally, as you can see from above we know a lot more about our data and have many more ideas on how we can answer this problem of player evaluation.