How to build a voting recommendation engine using Twitter profiles

With the events of 2020 plus the polarization in this country, it’s nearly impossible to find someone who doesn’t have an opinion (good or bad) on the President of the United States. However, this year it’s also become more clear how important local politicians and other elected officials are to our day-to-day lives. President Barack Obama said it best in his recent Medium post discussing the George Floyd killing.
…the elected officials who matter most in reforming police departments and the criminal justice system work at the state and local levels
Arguably this is the same for most issues that we care about. For instance, if you don’t like how Covid-19 was handled, part of the blame may be on your local officials. Because of this, for my passion project at Metis I decided to build a recommendation engine that would recommend local politicians you should vote for in your Bay Area county. At the very least, I wanted to help myself be a more informed local voter!
Data Collection
In a previous project, I predicted which political party people will vote for based on how they answer personal questions. Initially, I thought I would recommend local politicians based on the same dataset but we don’t know how politicians would answer these questions. In other words, the dataset I wanted didn’t really exist. These days, Twitter is popular enough that most politicians will use it pretty frequently. Thus, I decided to generate my own dataset and find similarities by comparing Twitter profiles. I used the GetOldTweets API to scrape tweets for all of them. Below is an example of an API call I ran in command line to scrape tweets:
GetOldTweets3 --username "SpeakerPelosi" --since 2019-03-03 --until 2020-03-03 --maxtweets 1000
There were 108 politicians running for either State Senate, State Assembly or the U.S. House of Representatives on March 3rd, 2020. After scraping, I realized only 61% of those politicians had a “useful” Twitter profile which means they had more than 10 tweets in the year preceding the election. Splitting this out by party: 83% of democrats had a “useful” profile and only 30% of Republicans could say the same. Because of this, I decided not to include even more local level politicians in this model as the percentage of them with usable Twitter profiles would probably be less. So we’re already seeing the limits of using Twitter and on focusing on the Bay Area. Here the Democrats tend to dominate the elections and this model will be biased towards picking Democrats as a result.
Vectorization
Next, I cleaned the data and then used TF-IDF to create a document-term matrix. This tells us how often a term appeared in each document (i.e. tweet).
tfidf = TfidfVectorizer(stop_words=custom_stop_words,ngram_range=(1,3), min_df = 5, max_df=.9, binary=True)
doc_word = tfidf.fit_transform(result)
doc_word_df = pd.DataFrame(doc_word.toarray(),index=df.drop_duplicates(),columns=tfidf.get_feature_names())
Afterwards, I summed up the columns of the matrix to get a one row politician-term vector. Essentially, this tells you often a politician uses various words because higher values for a word will mean they used that word across many tweets.
#sum up all columns
data = np.zeros((1,len(doc_word_df.columns)))
for i,column in enumerate(doc_word_df.columns):
data[0,i] = doc_word_df[column].sum()
#put the sums into a new dataframe
final = pd.DataFrame(data,index=[twitter_handle], columns=doc_word_df.columns)
The final result is what you see below:

Once we add other politicians the matrix looks like this:
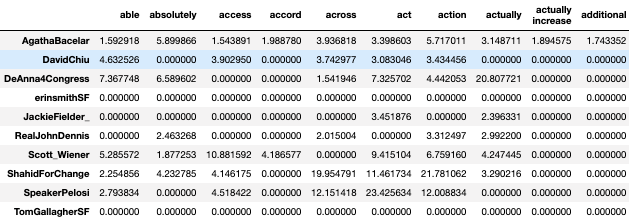
Sentiment Analysis
So now we have vectors for all politicians and can use similarity metrics like cosine similarity or euclidean distance to figure out who each politician is most similar to. I tested the recommendation engine at this point and it did relatively ok but I did notice one worrying result. If you looked at the values for a controversial topic like guns, you’ll see something like this:
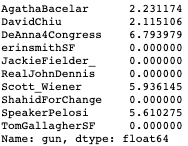
According to this, Scott Weiner and DeAnna Lorraine used the word gun the most. If you knew nothing about these politicians you might think they were similar but from a quick glance at the tweets we see very different sentiments:

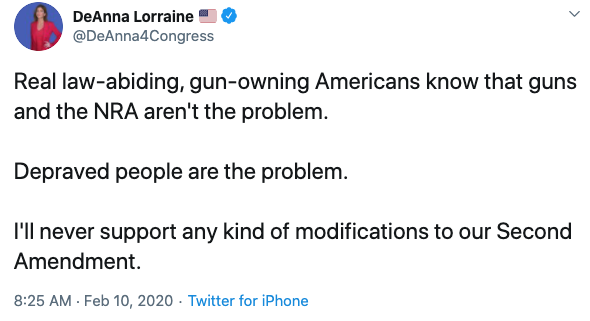
Two very different beliefs on guns! Sentiment Analysis should provide help here as one person is more positive about guns and the other is more negative. But how should we add sentiment analysis? I experimented and saw that adding a general sentiment column is not good enough given that the politician term vectors have thousands of columns. So I decided to take the top 200 words that each politician used, find the sentiment for each one and input a new column for each word’s sentiment in the politician-term vector. However, since I used VaderSentiment for this the sentiment analysis output is actually 4 things: measures of positive sentiment, negative sentiment, neutral sentiment and compound (i.e. total) sentiment. So ultimately I added 4 new sentiment columns per top word. Here’s how this looks for a couple of words:
Nancy Pelosi’s sentiment ratings for tweets where she mentioned the word “Democrat”:

Nancy Pelosi’s sentiment ratings for tweets where she mentioned Senate Majority Leader Mitch McConnell’s Twitter username:

As you can see she is more negative than positive when discussing Mitch McConnell and more positive than negative when discussing democrats. This is also visible in the compound ranking.
Similarity
Great, now we are ready to make some recommendations. What similarity metric should we use to provide them? This answer was pretty simple. I didn’t want the variable lengths of tweets to influence results so I used cosine similarity rather than euclidean distances. By experimenting with both, the results also show that this is a better method. To understand how exactly I incorporated sentiment analysis and cosine similarity check out the functions create_sentiment_vectors, get_similarities, and recommendation in twitter_recommender_api.py.
Final Result
For my specific use case, I wanted to give recommendations for any inputted twitter handle and recommend the top choice in each political contest in a county. Below you can see the results of the model when I inputted Joe Biden’s twitter feed and San Francisco as my county.

Voila! We have built a recommendation engine for Bay Area politicians! I really hope this was useful and if you have any questions you can reach me at samirthanedar@gmail.com. In the meantime, please VOTE this November!
For access to all the code for this project you can go to Github here. You can also test the recommendation engine here.